
Hydrothemen Nr. 39 / November 2020
24.11.2020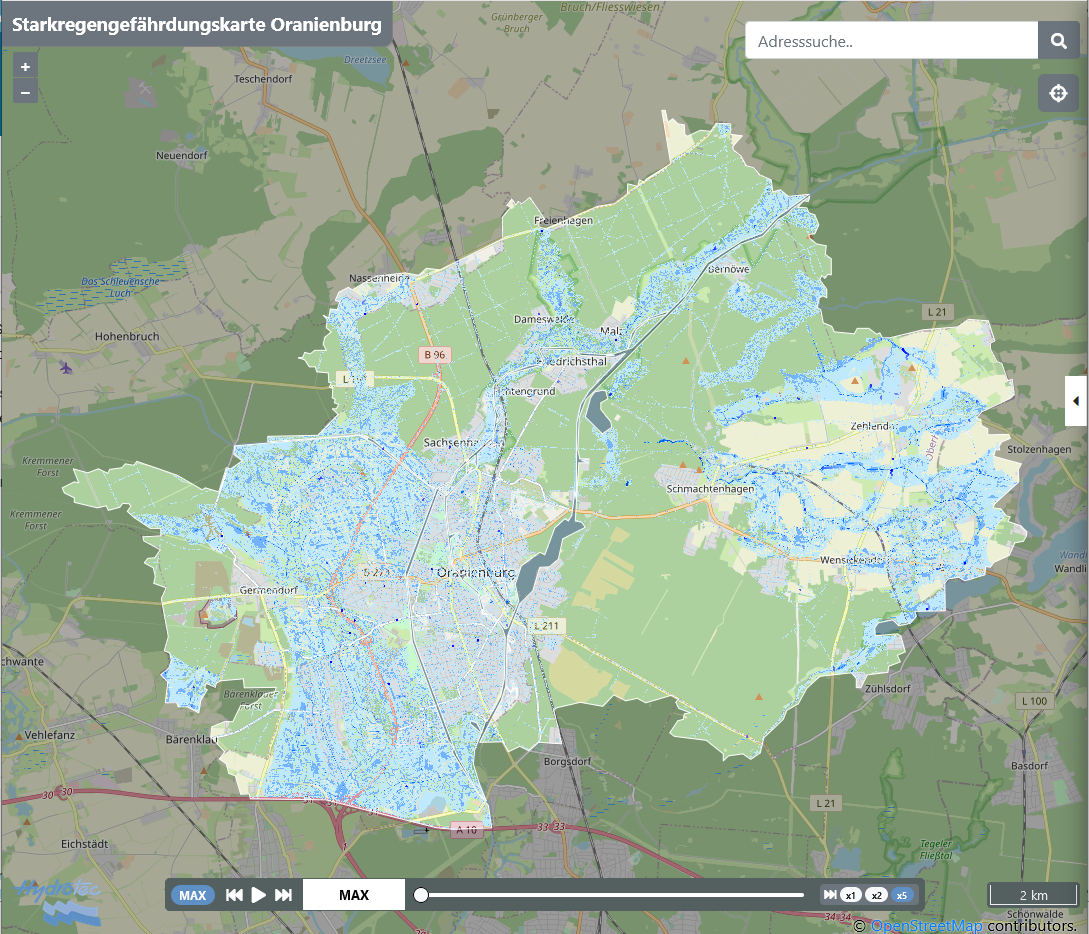
Starkregen WebViewer Oranienburg
26.11.2020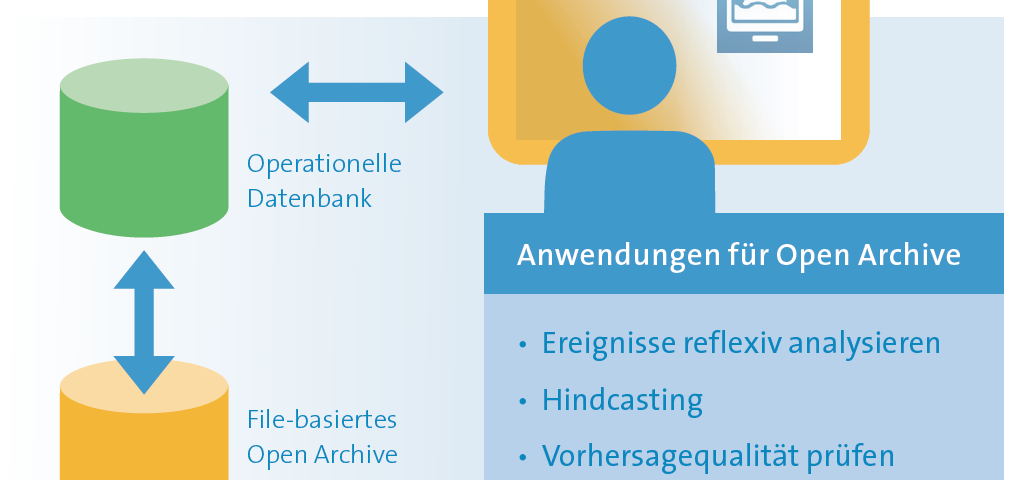
Prognose-Plattform Delft-FEWS erweitert um Archiv-Modul „OpenArchive“
 Das Delft FEWS Modul OpenArchive bietet die Möglichkeit, alle im Vorhersagesystem verwendeten Daten komfortabel und dauerhaft in ein Archiv zu überführen. Anwender können auf diese zyklisch oder ereignisbezogen archivierten Daten sehr einfach wieder zugreifen und diese für Auswertungen und spätere Überprüfungen nutzen. Das Laden der Daten aus dem Archiv erfolgt direkt über die Delft-FEWS-Oberfläche.
Das Delft FEWS Modul OpenArchive bietet die Möglichkeit, alle im Vorhersagesystem verwendeten Daten komfortabel und dauerhaft in ein Archiv zu überführen. Anwender können auf diese zyklisch oder ereignisbezogen archivierten Daten sehr einfach wieder zugreifen und diese für Auswertungen und spätere Überprüfungen nutzen. Das Laden der Daten aus dem Archiv erfolgt direkt über die Delft-FEWS-Oberfläche.
OpenArchive sorgt damit einerseits für eine Entlastung des operationellen Vorhersagebetriebs von nicht mehr benötigten Daten und gewährleistet andererseits, dass diese Daten mit wenig Aufwand verfügbar sind. Hydrotec hat OpenArchive bereits in mehrere Delft-FEWS-Systeme integriert und kundenspezifisch angepasst.
Daueraufgaben Datenspeicherung und -archivierung
Die Speicherung von Daten und Zeitreihen ist eine grundlegende Aufgabe bei jeder Tätigkeit des Wasserressourcenmanagements. Beobachtungen/Messungen, meteorologische Vorhersagen, historische Modellsimulationen und Modellvorhersagen sind zu erfassen, für ihren Einsatzbereich aufzubereiten und zu verwalten.
Für den operationellen Betrieb eines Abflussvorhersagesystems sind hauptsächlich die aktuellen Mess- und Prognosedaten von Interesse. Deshalb werden die importierten Zeitreihen und Simulationsergebnisse nur für einen begrenzten Zeitraum im System vorgehalten. Um die operationelle Datenbank möglichst klein zu halten, werden Daten und Prognoseläufe, die nicht mehr erforderlich sind, kontinuierlich gelöscht oder archiviert.
Die Archivierung von Daten gewinnt zunehmend an Gewicht, damit Abläufe oder Entscheidungen rückwirkend nachvollziehbar bleiben. Optimalerweise behalten die archivierten Daten dabei ihre Struktur und sind leicht wieder zu reaktiveren.
Delft-FEWS und OpenArchive: nahtlose Integration
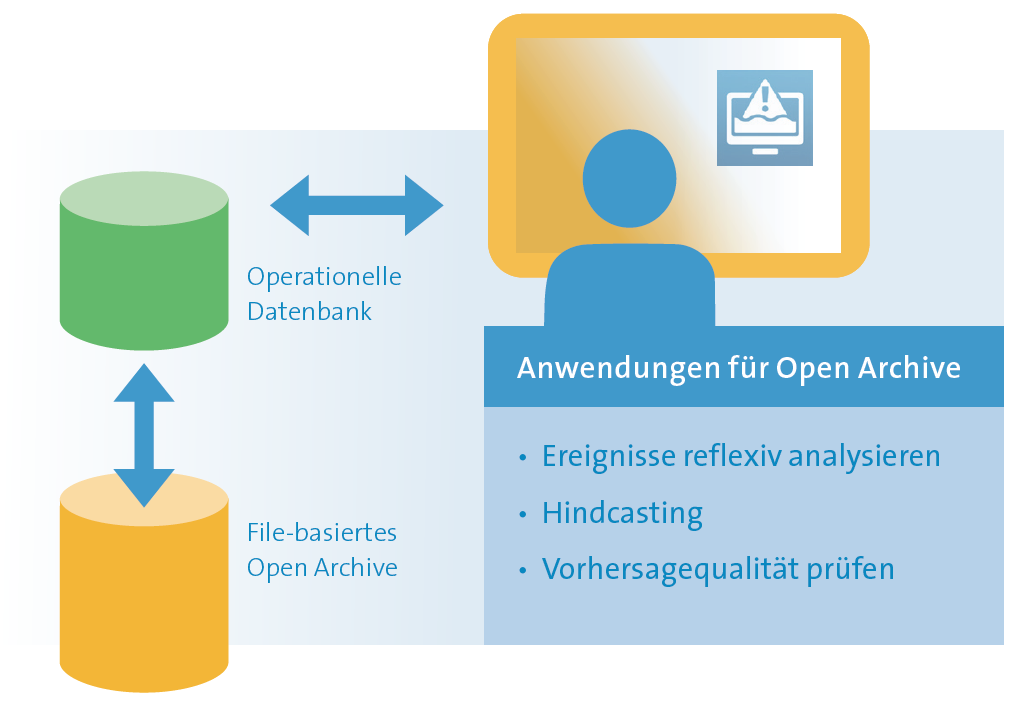 Das Delft FEWS Modul OpenArchive ist eine dateibasierte Speicherlösung, auf deren Daten die Anwender ganz unkompliziert über einen Katalog zugreifen können. Die Daten werden durch automatisierte Workflows in das OpenArchive exportiert und damit archiviert. Werden im Archiv abgelegte Daten zur Visualisierung oder Nachsimulation vergangener Ereignisse benötigt, können Anwender sie im Client/Server-System abfragen, in ihr Display „zurückholen“ und nahtlos mit ihnen arbeiten.
Das Delft FEWS Modul OpenArchive ist eine dateibasierte Speicherlösung, auf deren Daten die Anwender ganz unkompliziert über einen Katalog zugreifen können. Die Daten werden durch automatisierte Workflows in das OpenArchive exportiert und damit archiviert. Werden im Archiv abgelegte Daten zur Visualisierung oder Nachsimulation vergangener Ereignisse benötigt, können Anwender sie im Client/Server-System abfragen, in ihr Display „zurückholen“ und nahtlos mit ihnen arbeiten.
OpenArchive ermöglicht es über die Speicherung von Zeitreihendaten und Schlüsselkurven hinaus, Prognosedaten (die durch mehrere Prognosezeitpunkte gekennzeichnet sind) und zugehörige informative Daten wie Textberichte, Kommunikationsprotokolle, Modellzustände, Datenbank-Snapshots usw. in einem Paket zu speichern und leicht wieder verfügbar zu machen.
Besondere Ereignisse definieren
Kunden können Zeiträume mit Hochwasser, Niedrigwasser oder bestimmten Steuerungsvorgängen als besondere Ereignisse definieren. Daten zu diesen Zeiträumen werden in OpenArchive gekennzeichnet und erhalten z. B. eine längere Verweildauer im Archiv. So stehen die Ergebnisse des Vorhersagesystems und deren entsprechende Warnungen sowie die Effektivität der Hochwasserschutzmaßnahmen länger für nachträgliche Analysen zur Verfügung. Diese Ereignisdatensätze machen im Betrieb getroffene Entscheidungen rückwirkend nachvollziehbar und sie können z. B. zur Klärung von Rechtsstreitigkeiten herangezogen werden.
In OpenArchive sind unterschiedliche Ereignistypen definierbar, denen bestimmte zu speichernde Datensätze zugeordnet sind. Zusätzlich können die Ereignisse für bestimmte Einzugsgebiete und Zeiträume abgegrenzt werden.
Verbreitung von Vorhersagen vereinfachen
Vorhersagen werden häufig per Internet an beteiligte Akteure verbreitet. Das Delft FEWS Modul OpenArchive vereinfacht und automatisiert die Verbreitung von Vorhersagen, indem es Web-Viewern ermöglicht, direkt auf das Archiv zuzugreifen und die dort schon abgelegten Vorhersagedaten in einer Browser-Umgebung zu visualisieren. Damit entfällt das händische Verschieben von Daten aus einem Vorhersagesystem auf HTML-Seiten oder an bestimmte Ablageorte.
Hindcasting – Testen mit echten Daten
Beim Hindcasting werden Vorhersagen für Zeiten in der Vergangenheit erstellt, wobei nur Daten verwendet werden, die zu diesem Zeitpunkt verfügbar waren. Delft-FEWS-Anwender können aus OpenArchive vergangene Wettervorhersagen abrufen, um Abflussdaten zu erzeugen, die sie für ein Hindcasting verwenden möchten.
Einsatzbereiche für Hindcasting sind das Testen neuer Modelle oder anderer Prognoseroutinen wie Datenassimilation oder statistische Nachbearbeitung. Im Falle von hydrologischen Vorhersagen schließt dies auch mehrere Wettervorhersagen ein, die zum Zeitpunkt der Vorhersage verfügbar waren. Jeder Hindcast sollte dann durch eine bestimmte Wettervorhersageerzeugt werden.
Qualität von Vorhersagen prüfen
Ein weiterer Einsatzbereich des OpenArchive ist die Prognoseverifizierung, die eine Aussage über die Qualität einer Reihe von Vorhersagen ermöglicht. Dabei werden alte Prognosen nachträglich mit Messwerten verglichen, wenn sie verfügbar sind. Um die Prognosen verifizieren zu können, müssen sie dementsprechend langfristiger gespeichert werden. Das Verifizierungstool in Delft-FEWS greift auf diese archivierten Vorhersagedaten zu, vergleicht diese mit den „verifizierenden“ Beobachtungsdaten und gibt an, inwieweit die Vorhersage zutraf.
Technik des Delft FEWS Modul OpenArchive
 Hauptkomponenten des OpenArchive sind die Datenspeicherung und deren Katalogisierung. Die Datenspeicherung besteht aus Verzeichnissen und deren entsprechenden Metadateien. Ein sogenannter Harvester greift auf die Metadateien zu und indiziert die Dateien danach. Die Suche nach bestimmten Daten oder Ereignissen erfolgt über den Katalog, der durch Elasticsearch auf die bereits indizierten Daten zugreift. Für den Abruf der archivierten Daten bzw. die nahtlose Integration verwendet OpenArchive einen THREDDS Datenserver, der unterschiedliche Protokolle zum Datenzugriff bietet (HTTP, OPeNDAP, WMS und WCS).
Hauptkomponenten des OpenArchive sind die Datenspeicherung und deren Katalogisierung. Die Datenspeicherung besteht aus Verzeichnissen und deren entsprechenden Metadateien. Ein sogenannter Harvester greift auf die Metadateien zu und indiziert die Dateien danach. Die Suche nach bestimmten Daten oder Ereignissen erfolgt über den Katalog, der durch Elasticsearch auf die bereits indizierten Daten zugreift. Für den Abruf der archivierten Daten bzw. die nahtlose Integration verwendet OpenArchive einen THREDDS Datenserver, der unterschiedliche Protokolle zum Datenzugriff bietet (HTTP, OPeNDAP, WMS und WCS).
Zusätzlich können die Daten von Drittanwendern über eine PI-Webservice-Schnittstelle durch THREDDS abgerufen werden.
Juan Sebastian Salva, M.Sc., Dr.-Ing. Oliver Buchholz